Linux部署联邦学习(仿真)
1 环境
操作系统:Ubuntu 24.04
2 安装docker
相关配置教程:
Docker Hub中拉取镜像时出现超时问题该如何做? - 嗨,阿良 - 博客园
GitHub - dongyubin/DockerHub: 2024年12月更新,目前国内可用Docker镜像源汇总,DockerHub国内镜像加速列表,🚀DockerHub镜像加速器
3 建立配置文件
3.1 dockerfile 配置
dockerfile 是一个文本文件,其中包含了一系列命令,用于定义构建 Docker 镜像的步骤。使用 dockerfile可以为联邦学习部署环境创建一致且可重复的环境配置,确保每个节点都有一致的开发和运行环境。
dockerfile文件配置如下:
# 使用官方 Python 3.9 镜像
FROM python:3.9
# 设置工作目录
WORKDIR /app
# 安装依赖
RUN pip install --upgrade pip
# 使用清华源,下载速度快
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==2.18.0
RUN pip install pandas==2.2.3 numpy==1.23.0 scikit-learn==1.6.0 matplotlib==3.9.3 plotly==5.24.1 flask==3.1.0
# 复制本地代码到容器
# COPY federated_learning.py /app/federated_learning.py
COPY . /app
# 默认启动客户端,federated_learning.py是运行联邦学习的脚本文件
CMD ["python", "federated_learning.py"]
3.2 docker compose 部署流程
docker compose用于定义和运行多个容器的应用。对于联邦学习,通过docker compose可以方便地定义多个容器及其之间的服务链接,简化整个部署过程。
docker-compose.yml文件配置如下
version: '3'
services:
# 联邦学习的中心服务器
server:
build: .
container_name: federated_server
volumes:
- ./federated_learning.py:/app/federated_learning.py # 将训练脚本挂载到服务器容器中
command: ["python", "federated_learning.py", "--mode", "server"]
networks:
- federated_network # 设定容器通信网络
ports:
- "5000:5000" # 服务器端开放端口,客户端通过这个端口访问服务器
client1:
build: .
container_name: federated_client1
volumes:
- ./federated_learning.py:/app/federated_learning.py
- /home/ysy/FL/FLdocker:/app
command: ["python", "federated_learning.py", "--mode", "client", "--client_id", "1"]
networks:
- federated_network
depends_on: # 服务依赖,代表该容器会在server启动后才紧接着启动
- server
environment:
- CLIENT_DATA_FILE=./Data/task_001.csv # 指定客户端1使用的CSV文件
client2:
build: .
container_name: federated_client2
volumes:
- ./federated_learning.py:/app/federated_learning.py
command: ["python", "federated_learning.py", "--mode", "client", "--client_id", "2"]
networks:
- federated_network
depends_on:
- client1
environment:
- CLIENT_DATA_FILE=./Data/task_005.csv
client3:
build: .
container_name: federated_client3
volumes:
- ./federated_learning.py:/app/federated_learning.py
command: ["python", "federated_learning.py", "--mode", "client", "--client_id", "3"]
networks:
- federated_network
depends_on:
- client2
environment:
- CLIENT_DATA_FILE=./Data/task_009.csv
client4:
build: .
container_name: federated_client4
volumes:
- ./federated_learning.py:/app/federated_learning.py
command: ["python", "federated_learning.py", "--mode", "client", "--client_id", "4"]
networks:
- federated_network
depends_on:
- client3
environment:
- CLIENT_DATA_FILE=./Data/task_010.csv
client5:
build: .
container_name: federated_client5
volumes:
- ./federated_learning.py:/app/federated_learning.py
command: ["python", "federated_learning.py", "--mode", "client", "--client_id", "5"]
networks:
- federated_network
depends_on:
- client4
environment:
- CLIENT_DATA_FILE=./Data/task_014.csv
networks:
federated_network:
driver: bridge # 所有容器都将通过这个网络进行通信
3.3 配置联邦学习代码
我们用联邦学习训练一个LSTM模型,用以预测任务执行进度
数据集格式如下:
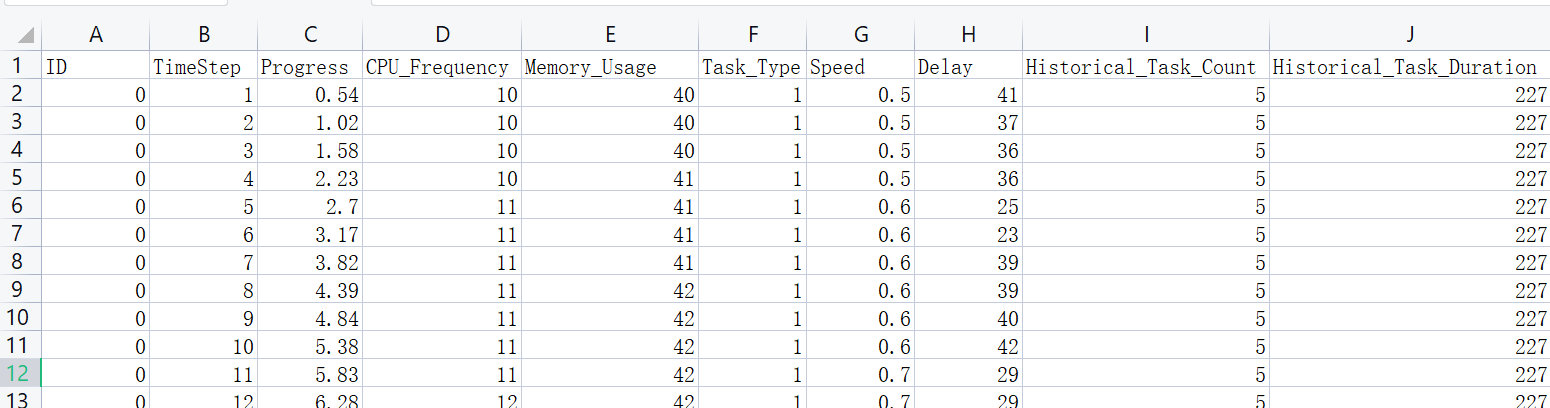
联邦学习的训练流程为:
- 初始化全局模型:服务器初始化全局模型权重。
- 客户端训练:客户端从服务器获取全局模型权重,进行本地训练,并将更新后的权重发送到服务器。
- 权重聚合:服务器聚合客户端上传的权重,更新全局模型权重。
- 全局模型分发:服务器将更新后的全局模型权重分发给客户端,客户端使用新的全局模型权重进行下一轮训练。
我们编写的代码如下:
# federated_learning.py
import tensorflow as tf
import numpy as np
import pandas as pd
import argparse
import os
import json
import time
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from flask import Flask, request, jsonify
import requests # 用于与服务器通信
import warnings
warnings.filterwarnings('ignore', category=UserWarning, module='keras')
# 初始化 Flask 应用
app = Flask(__name__)
10
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, required=True, choices=['server', 'client'], help="运行模式:server 或 client")
parser.add_argument('--client_id', type=int, help="客户端ID,仅在客户端模式下需要")
args = parser.parse_args()
# 1. 定义LSTM模型
def create_model():
model = Sequential()
model.add(LSTM(32, input_shape=(None, 8), return_sequences=False))
model.add(Dense(1)) # 输出任务进度
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['mean_absolute_error'])
return model
# 从指定文件夹加载CSV文件
def load_data_from_file(file_path):
df = pd.read_csv(file_path)
# 数据预处理
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(
df[['Progress', 'CPU_Frequency', 'Memory_Usage', 'Task_Type', 'Speed', 'Delay', 'Historical_Task_Count',
'Historical_Task_Duration']]
)
# 构建LSTM的输入数据格式:时间窗口
def create_sequences(data, sequence_length):
sequences = []
labels = []
for i in range(len(data) - sequence_length):
sequences.append(data[i:i + sequence_length])
labels.append(data[i + sequence_length, 0]) # 任务进度作为标签
return np.array(sequences), np.array(labels)
sequence_length = 10 # 时间窗口大小
X, y = create_sequences(scaled_data, sequence_length)
return X, y
global_weights = None # 初始化全局模型权重
# 服务器端:聚合客户端模型
def server_aggregation(client_weights):
# 进行加权平均(所有客户端权重相等)
average_weights = [np.mean([client_weight[i] for client_weight in client_weights], axis=0)
for i in range(len(client_weights[0]))]
return average_weights
# 客户端:训练模型并将权重返回给服务器
def client_training(client_id, file_path,global_weights):
# 加载客户端数据并进行训练
X, y = load_data_from_file(file_path)
# 划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# 构建模型
model = create_model()
# 如果有全局权重,则设置模型权重
if global_weights is not None:
global_weights = [np.array(weight) for weight in global_weights]
model.set_weights(global_weights)
history = model.fit(X_train, y_train, epochs=100, batch_size=32,verbose=0, validation_data=(X_test, y_test))
# 评估模型
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(f"Global model evaluation results: MSE={mse}, MAE={mae}, RMSE={rmse}")
# 获取训练后的权重
weights = model.get_weights()
# 将权重转换为列表,方便 JSON 序列化
weights_list = [weight.tolist() for weight in weights]
return weights_list
# 服务器端:存储客户端的权重
client_weights = []
# 客户端上传权重的 API 路由
@app.route('/update_weights', methods=['POST'])
def update_weights():
updated_weights = request.json # 获取客户端上传的权重
client_weights.append(updated_weights) # 添加到 client_weights 列表
# 如果收集到了所有客户端的权重(比如假设有5个客户端),就进行聚合
if len(client_weights) == 5: # 假设我们有5个客户端
global global_weights # 在函数内部修改全局变量
global_weights = server_aggregation(client_weights)
if global_weights:
app.logger.info("Global model updated.")
else:
print("No client weights received.")
# 清空 client_weights,准备下一轮的权重更新
client_weights.clear()
return jsonify({"status": "success"}), 200
# 服务器端:发放全局模型
@app.route('/get_global_model', methods=['GET'])
def get_global_model():
if global_weights is None:
return jsonify({"status": "error", "message": "No global model yet."}), 400
# 将每个 NumPy 数组转换为列表
global_weights_serializable = [weight.tolist() for weight in global_weights]
# 返回序列化后的 global_weights
return jsonify({"status": "success", "global_weights": global_weights_serializable}), 200
# 客户端:获取全局模型权重
def get_global_model():
response = requests.get("http://server:5000/get_global_model")
if response.status_code == 200:
return response.json()['global_weights']
else:
return None
# 客户端:执行联邦学习迭代细节
def federated_learning_iteration(client_id, file_path):
global_weights = get_global_model() # 获取全局模型权重
if global_weights is None:
print("No global model found, initializing model with random weights.")
global_weights = initialize_global_model() # 初始化全局模型的权重(你可以使用任何初始化方法)
if global_weights is not None:
updated_weights = client_training(client_id, file_path, global_weights)
print(f"Client {client_id} updated weights.")
# 将更新后的权重发送到服务器
response = requests.post("http://server:5000/update_weights", json=updated_weights)
print(f"Response from server: {response.status_code}")
# 如果返回状态是等待其他客户端,则客户端将继续等待
if response.status_code == 200:
print(f"Client {client_id} is waiting for other clients to finish this round.")
while True:
# 检查服务器是否已更新全局模型,且所有客户端已完成
response = requests.get("http://server:5000/get_global_model")
if response.status_code == 200:
new_global_weights = response.json().get('global_weights', None)
if new_global_weights != global_weights:
print(f"Client {client_id} received updated global model. Proceeding to next round.")
break # 收到全局模型,开始下一轮训练
else:
print(f"Client {client_id} waiting for global model update.")
time.sleep(30) # 每30秒检查一次
# 客户端:执行多个训练周期(并行进行),客户端迭代
def federated_learning_loop(file_path, rounds=10, num_clients=5):
for round in range(rounds):
print(f"Starting round {round + 1}")
verbose=None
# 同时为每个客户端执行训练
client_ids = range(num_clients) # 假设有 `num_clients` 个客户端
# 1. 所有客户端并行执行训练,并上传权重
for client_id in client_ids:
federated_learning_iteration(client_id, file_path) # 客户端执行本地训练并上传权重
print(f"Round {round + 1} completed.")
# 初始化全局模型
def initialize_global_model():
# 创建一个新的模型并返回其权重10
model = create_model() # 使用之前定义的 `create_model()` 函数
initial_weights = model.get_weights() # 获取模型的初始权重
# 将权重转换为列表以便于 JSON 序列化
initial_weights_list = [weight.tolist() for weight in initial_weights]
return initial_weights_list
# 服务器模式:启动 Flask 服务器并等待客户端上传更新
if __name__ == "__main__":
if args.mode == 'server':
print("Server mode: waiting for client updates...")
app.run(host="0.0.0.0", port=5000) # 启动 Flask 服务器,监听 5000 端口
elif args.mode == 'client':
print(f"Client {args.client_id} mode: training...")
# 从环境变量或命令行参数获取客户端要使用的 CSV 文件路径
file_path = os.getenv('CLIENT_DATA_FILE', None) # 这里根据实际情况修改文件路径
if file_path:
print(f"客户端正在训练:{file_path}")
federated_learning_loop(file_path, rounds=10, num_clients=5) # 假设有5个客户端
print(f"Client {args.client_id} completed all rounds.")
else:
print("未找到指定的数据文件路径!")
上述代码流程:
- 服务器启动:服务器启动 Flask 应用,监听端口 5000,等待客户端上传权重。
- 客户端启动:客户端从服务器获取全局模型权重,加载本地数据,进行训练,并将更新后的权重发送到服务器。
- 权重聚合:服务器在收到所有客户端的权重后,进行聚合并更新全局模型。
- 全局模型分发:服务器将更新后的全局模型权重分发给客户端,客户端使用新的全局模型权重进行下一轮训练。
- 重复迭代:重复上述过程,直到完成所有训练周期。
3.4 运行联邦学习
项目目录结构:
project_directory/
│
├── docker-compose.yml
├── dockerfile
├── federated_learning.py
├── Data/
│ ├── task_001.csv
│ ├── task_005.csv
│ ├── task_009.csv
│ ├── task_010.csv
│ └── task_014.csv
└── ...
首先启动容器:systemctl start docker
进入project_directory目录下:
执行命令:docker-compose up –build
启动 Docker Compose 项目,首次运行该命令会先下载环境依赖,需要等待一定时间
依赖安装结束之后,开始构建联邦学习的服务端和客户端:
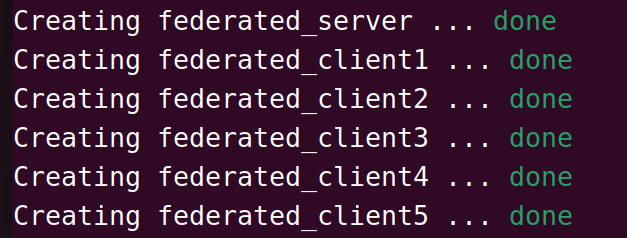
表示创建成功。
起始阶段,各客户端先使用初始全局模型各自进行训练:
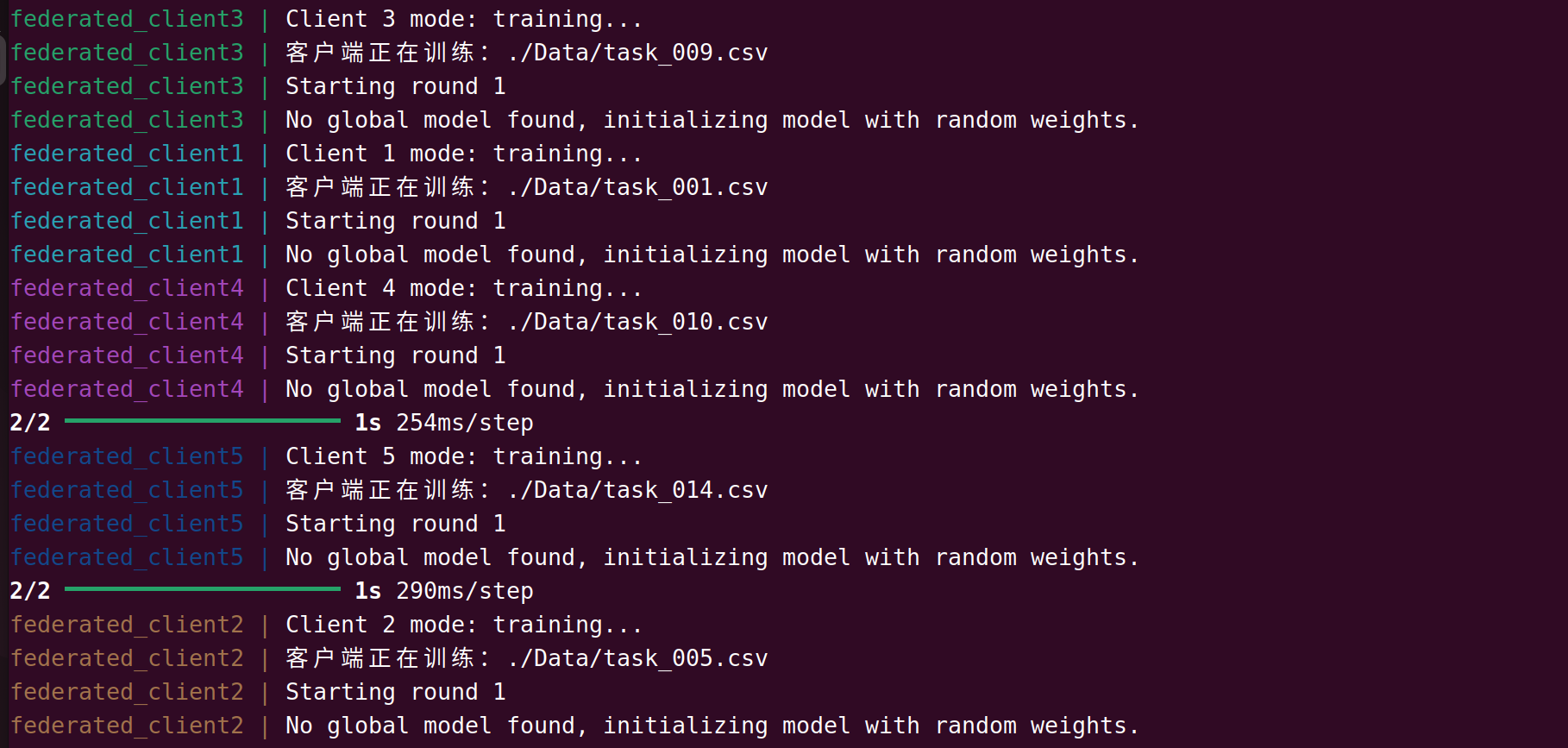
客户端使用数据进行本地模型训练,并上传模型权重到服务端:
(如果此时其它客户端还未上传权重,则已上传权重的客户端需等待)

获取到全局模型权重后,进入下一轮迭代:

服务器端获取到所有客户端上传的权重后,更新全局模型权重:

各客户端结束训练:
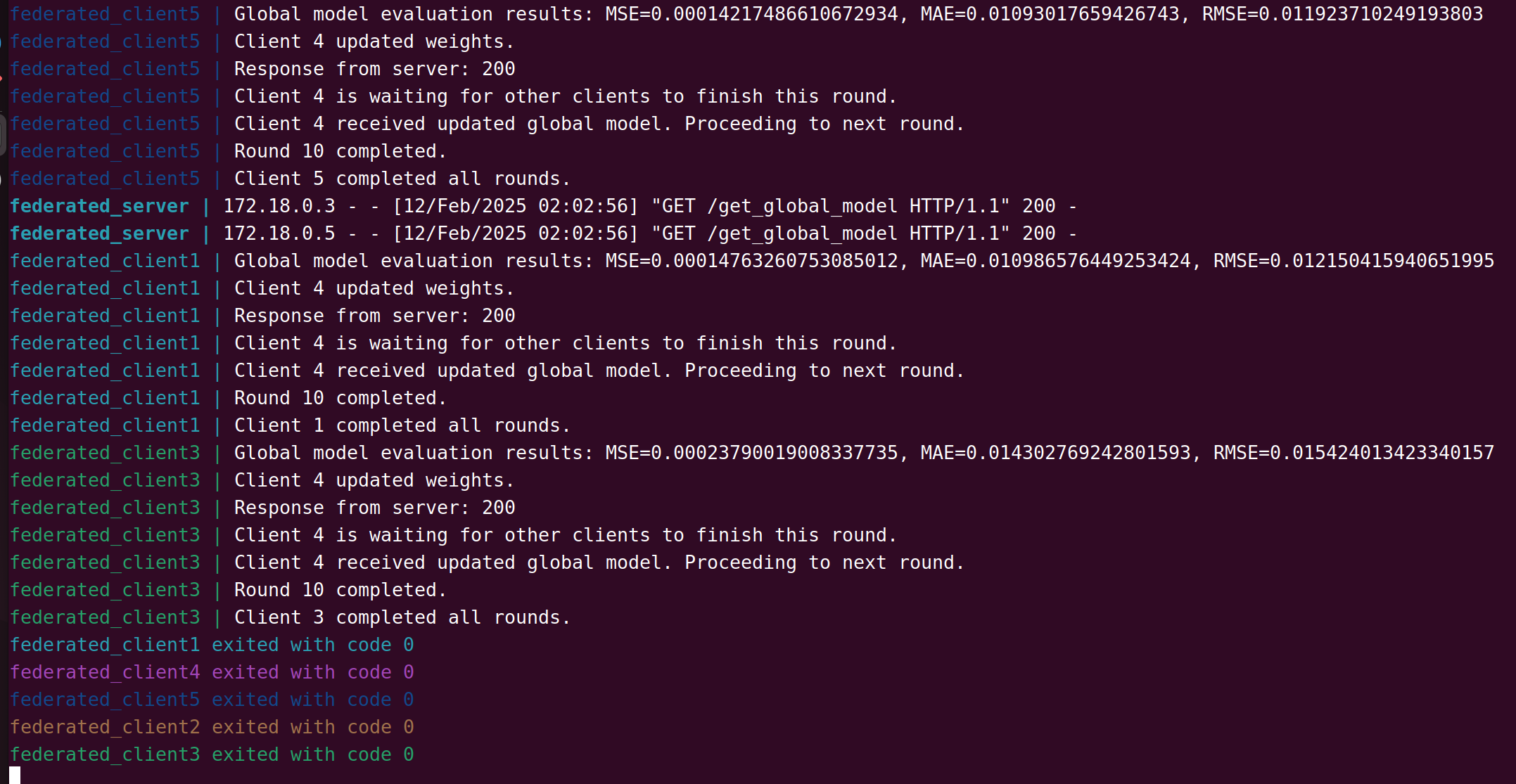
结束后,使用Ctrl+C退出服务端,然后执行命令:
docker-compose down 释放所有容器资源
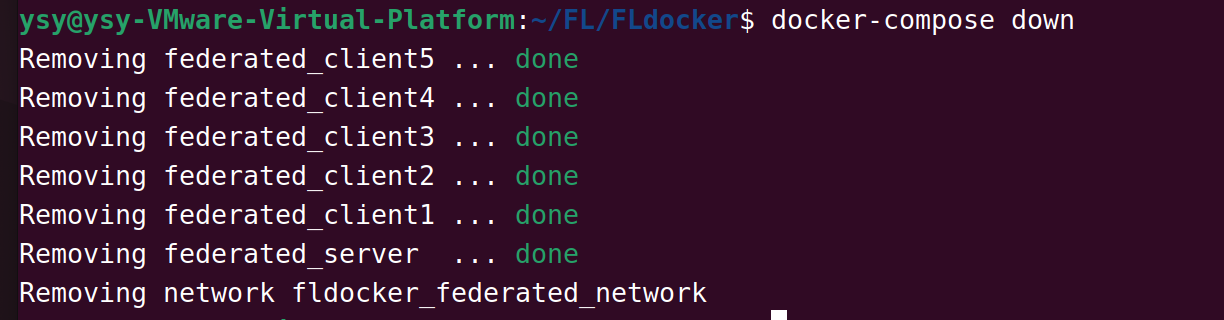
下次再启动联邦学习仿真时,再次执行docker-compose up –build即可
4.展望
未来计划:
在硬件平台上实现联邦学习