Stanford CS106L “Standard C++ Programming”课程
Stanford CS106L Standard C++ Programming 课程
课程链接:CS 106L: Standard C++ Programming (stanford.edu)
一.Types and Structs
1.最好不要使用using namespace std
在大型项目中,使用using namespace std;会存在以下几个问题:
- 命名冲突:使用using namespace std;会将所有std命名空间下的名称都引入当前命名空间,可能会与当前项目中的其他标识符冲突,导致编译错误。
- 可读性差:如果在项目中使用大量的命名空间,代码可能会变得难以阅读和理解,因为不知道哪个标识符映射到哪个命名空间。
- 可维护性差:在大型项目中,多人协作开发时,每个人编写的代码都可能使用不同的命名空间。如果在一个文件中使用 using namespace std;,则可能导致其他人的代码出现不可预期的结果,从而影响整个项目的质量。
2.C++是一种静态类型语言
在静态类型语言中,类型检查发生在编译时期,编译器会检查代码中的类型错误并提供警告或错误信息。在动态类型语言中,类型检查发生在运行时期,变量的类型可以在运行时动态改变,编译器不会进行静态类型检查。
在静态类型语言中,变量和表达式的类型需要在编码过程中显式定义,并且在编译时期进行类型检查。在动态类型语言中,变量的类型通常是根据赋值的值来推断的,不需要显式定义类型。
- 静态类型语言有:C/C++、Java、C#、Rust、Go、kotlin
- 动态类型语言有:Python、javascript、Ruby、PHP、R、Matlab、shell
3.auto类型
C++11新特性,让编译器自己推断数据类型,但是不等于说变量没有类型。
4.结构体struct成员变量初始化
Student s;
s.name = "Haven";
s.state = "AR";
s.age = 22;
//is the same as ...
Student s = {"Haven", "AR", 22}; //更简单
5.STL容器中的pair实际上就是一个struct结构体
二.Initialization & References
1.初始化
(1)直接初始化
int valInt = 3.00; // valInt => 3
int valInt1(4.5); // valInt1 => 4
C++ 不在乎初始化传入的数值是否为整数 (传入浮点数会转换成整数)
不安全
(2)常规初始化
C++11新特性
int valInt{1}; // 正确
int valInt1{3.14}; // 无法通过编译
还适用于Map,vector、struct等数据结构。既安全,通用性也比较强。
// std::map
std::map<std::string, int> ages{
{"Nanomoa", 20},
{"Test", 21}
};
// std::vector
std::vector<int> vec{1, 2, 3, 4, 5};
// struct
struct Student {
std::string name;
int age;
};
Student stu;
stu.name = "Nanomoa";
stu.age = 20;
// 等同于下面
Student s = {"Nanomoa", 20};
(3)结构化绑定
C++17新特性
元组数据类型——tuple
std:tuple<int,float,std:string>first(4,2.1,"for");
结构化绑定允许我们在一行代码中声明多个变量,并将聚合类型的元素分别初始化为这些变量。这对于处理如std::pair、std::tuple、数组和结构体等类型的数据非常有用。

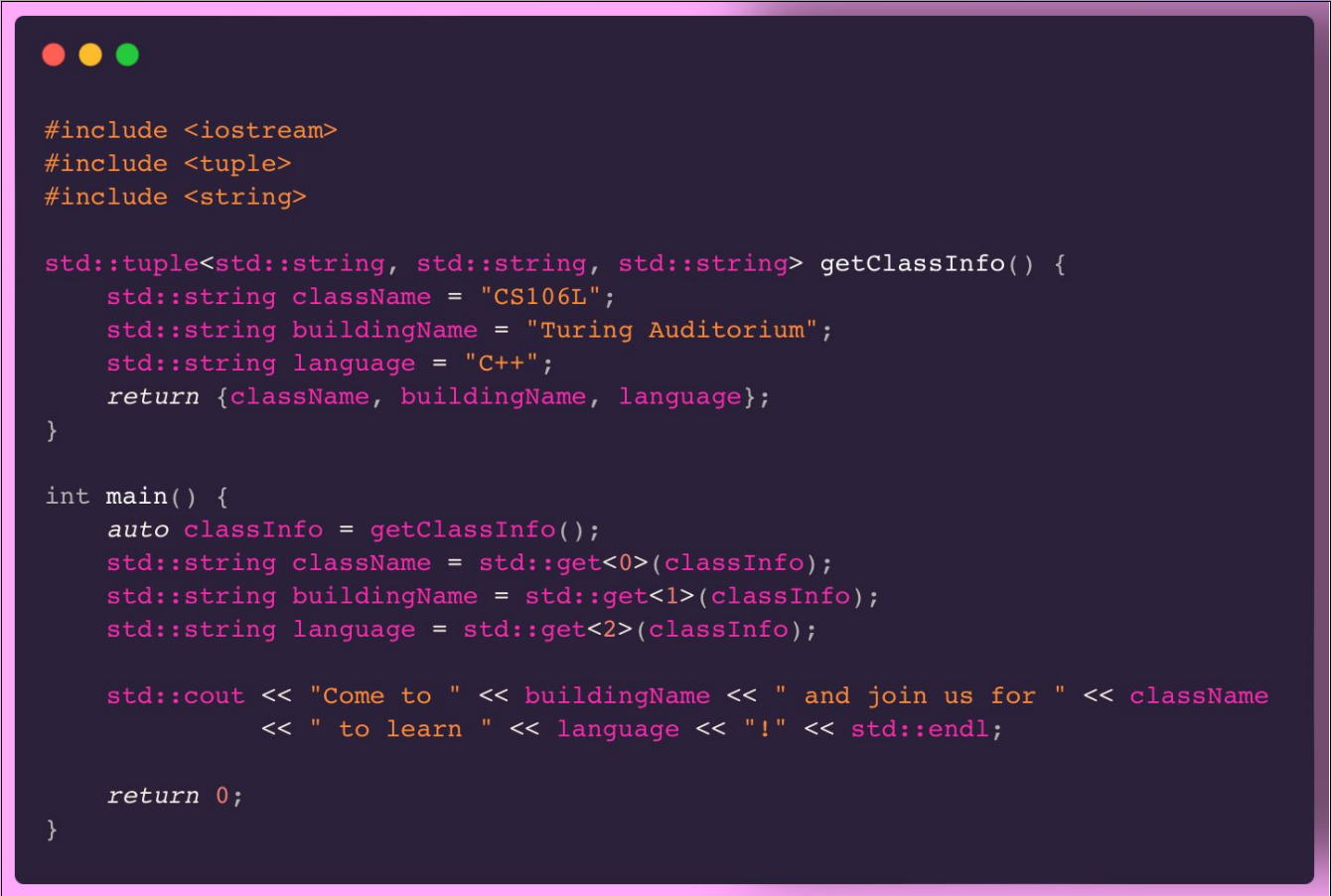
易错题:
// 传入此函数中的nums并没有被修改
void func(std::vector<std::pair<int, int>> &nums) {
for (auto [num1, num2] : nums) { // 此处通过结构化绑定copy了nums中当前pair的值
num1++; // 此处修改的是copy的pair, 而不是nums中的pair
num2++;
}
}
// 此函数中 nums 被修改
void func1(std::vector<std::pair<int, int>> &nums) {
for (auto& [num1, num2] : nums) { // 此处通过结构化绑定引用了nums中当前pair
num1++;
num2++;
}
}
2.左值、右值
在C++中,左值(lvalues)和右值(rvalues)是用来描述表达式的两种基本类别,区分它们的概念是C++11引入的右值引用(rvalue reference)。
左值(lvalues):
- 定义:左值是指表达式结束后依然存在的、具有内存位置的对象或表达式。
- 特点:左值可以出现在赋值语句的左边或右边,可以被取地址。
- 示例:变量、函数返回左值引用、具名对象。
右值(rvalues):
- 定义:右值是指表达式结束后就被销毁的临时对象,没有持久的内存位置。
- 特点:右值只能出现在赋值语句的右边,不能被取地址。
- 示例:字面常量、临时对象、函数返回非引用类型的临时变量、移动语义。
- 区分左值和右值的方法:
在C++中,引入了右值引用(rvalue reference)的概念,这是区分左值和右值的关键。右值引用通常用于移动语义,当一个对象被转移所有权时,它会被视为右值。通过这种方式,可以根据一个表达式是否能绑定到右值引用来区分左值和右值。
void foo(int& x) {
// 左值引用
}
void foo(int&& x) {
// 右值引用
}
int main() {
int a = 5; // a 是左值
int&& b = 10; // 10 是右值
foo(a); // a 是左值
foo(5); // 5 是右值
return 0;
}
在上面的例子中,foo(int& x)接受左值引用,而foo(int&& x)接受右值引用。通过这种方式,可以根据函数参数类型判断传递给函数的表达式是左值还是右值。右值引用的引入使得在C++中更容易区分左值和右值,这也为移动语义提供了基础。
注意: 不能将右值绑定到非 const 的左值,例:
int squareN(int& num) {
return std::pow(num, 2);
}
auto val = squareN(2); // 编译错误
3.const
使用 const 声明的对象不可修改,例:
std::vector<int> vec{1, 2, 3}; // 非 const
vec.push_back(4); // 可修改
std::vector<int>& ref_vec{vec}; // 引用
ref_vec.push_back(5);
const std::vector<int> const_vec{1, 2, 3}; // const
const_vec.push_back(4); // 编译错误, 不可修改
const std::vector<int>& ref_const_vec{const_vec}; // const 引用
ref_const_vec.push_back(4); // 不可修改
注意: 对于 const 声明的对象,不能为其声明 非const 的引用,例:
const std::vector<int> vec{1, 2, 3};
std::vector<int>& ref_vec{vec}; // 错误
const std::vector<int>& const_ref_vec{vec}; // 正确
4.C++编译
使用g++进行编译
g++ -std=c++11 main.cpp -o main #使用g++编译
三.stream
1.字符串流stringstream
int main() {
/// partial Bjarne Quote
std::string initial_quote = “Bjarne Stroustrup C makes it easy to shoot
yourself in the foot”;
/// create a stringstream
std::stringstream ss(initial_quote);
/// data destinations
std::string first;
std::string last;
std::string language, extracted_quote;
ss >> first >> last >> language;
std::cout << first << “ ” << last << “ said this: ”<< language << “ “ <<
extracted_quote << std::endl;
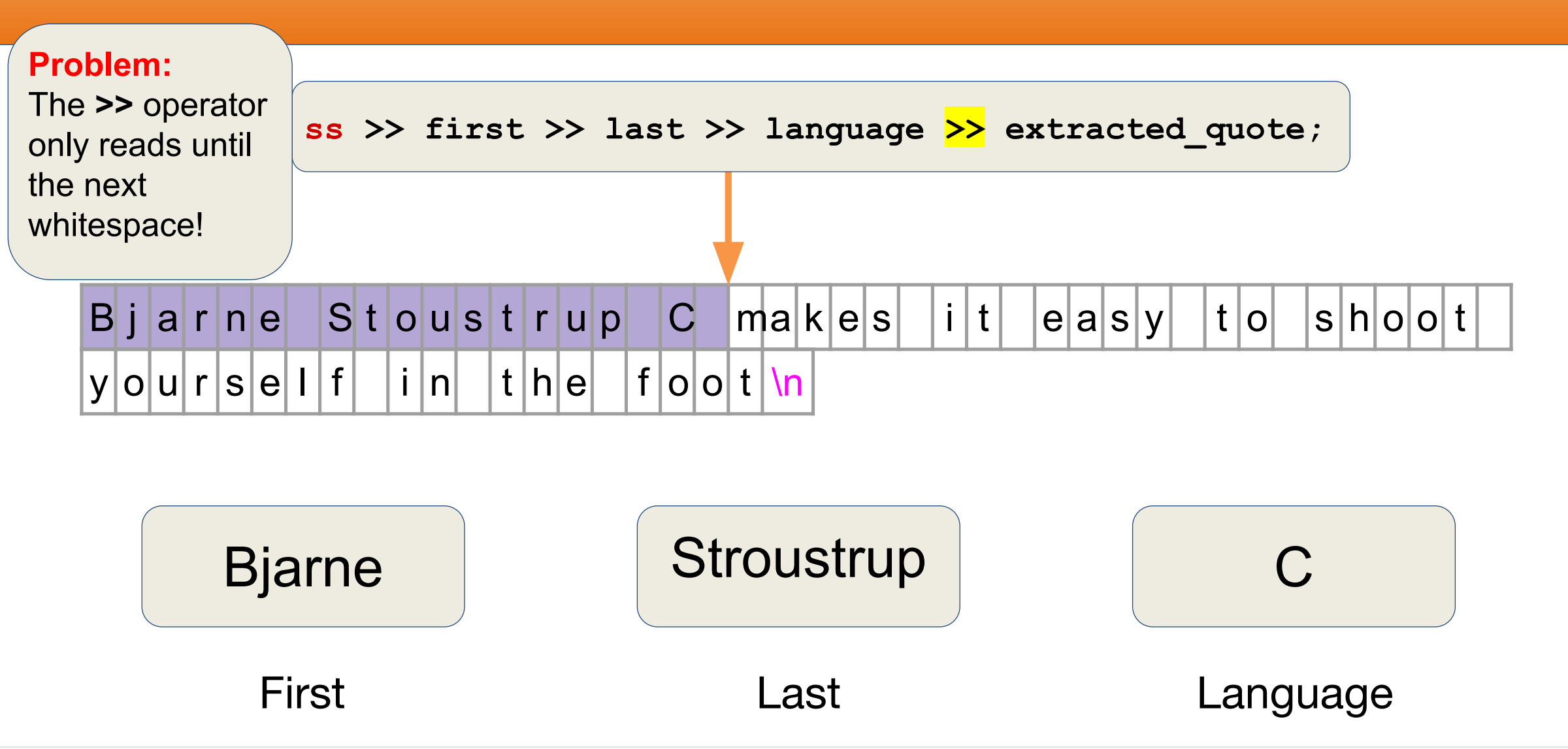
”»“只会读到下一个空格
所以引入了getline,能够读取含有空格的字符串 ,getline每到一个换行符就停止。
std:string str = "hello world";
std:stringstream ss(str);
std:string S;
std:getline(ss,S);
不推荐 std::getline 和 std::cin 同时使用,因为二者解析数据的方式不同。
比如:
void cinGetlineBug() {
double pi;
double tao;
std::string name;
std::cin >> pi;
std::getline(std::cin, name);
std::getline(std::cin, name);
std::cin >> tao;
std::cout << "my name is : " << name << " tao is :
" << tao << " pi is : " << pi << '\n';
}
四.container
1.三种顺序容器对比

2.Map和Set
map和unordered_map(hash_map)的区别(set差不多):
(1)使用方法不同
使用方法是最直观的区别,这两种结构虽然都在STL库中,但是所使用的头文件不同。
- map:#include
- unordered_map:#include
(2)底层数据结构不同
map是基于红黑树结构实现的。红黑树具有自动排序的功能,因此它使得map也具有按键(key)排序的功能,因此在map中的元素排列都是有序的。
unordered_map是基于哈希表(也叫散列表)实现的。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。散列表使得unordered_map的插入和查询速度接近于O(1)(在没有冲突的情况下),但是其内部元素的排列顺序是无序的。
(3)效率及稳定性不同
-
存储空间:unordered_map的散列空间会存在部分未被使用的位置,所以其内存效率不是100%的。而map的红黑树的内存效率接近于100%。
-
查找性能的稳定性:map的查找类似于平衡二叉树的查找,其性能十分稳定。例如在1M数据中查找一个元素,需要多少次比较呢?20次。map的查找次数几乎与存储数据的分布与大小无关。而unordered_map依赖于散列表,如果哈希函数映射的关键码出现的冲突过多,则最坏时间复杂度可以达到是O(n)。因此unordered_map的查找次数是与存储数据的分布与大小有密切关系的,它的效率是不稳定的。
优缺点及适用场景:
-
map:
- 优点:
- map元素有序(这是map最大的优点,其元素的有序性在很多应用中都会简化很多的操作);
- 其红黑树的结构使得map的很多操作都可在O(logn)下完成;
- map的各项性能较为稳定,与元素插入顺序无关;
- map支持范围查找。
- 缺点:
- 占用的空间大:红黑树的每一个节点需要保存其父节点位置、孩子节点位置及红/黑性质,因此每一个节点占用空间大。
- 查询平均时间不如unordered_map。
- 适用场景:
- 元素需要有序;
- 对于单次查询时间较为敏感,必须保持查询性能的稳定性,比如实时应用等等。
-
unordered_map
- 优点:
- 查询速度快,平均性能接近于常数时间O(1);
- 缺点:
- 元素无序;
- unordered_map相对于map空间占用更大,且其利用率不高;
- 查询性能不太稳定,最坏时间复杂度可达到O(n)。
- 适用场景:
- 要求查找速率快,且对单次查询性能要求不敏感。
3.容器适配器(container adapters)
在C++的标准库中,容器适配器(Container Adapter)是一种特殊的容器类,它们基于已有的容器提供了不同的接口和功能。容器适配器可以被看作是对底层容器的封装,以便于在特定场景下提供更简单、更方便的操作和语义。
标准库中提供了三种常见的容器适配器:
std::stack:栈(Stack)是一种遵循后进先出(Last-In-First-Out,LIFO)原则的数据结构。std::stack是基于底层容器(如std::deque、std::list或std::vector)封装而成的容器适配器,提供了栈的操作,如入栈(push)、出栈(pop)和访问栈顶元素(top)。std::queue:队列(Queue)是一种遵循先进先出(First-In-First-Out,FIFO)原则的数据结构。std::queue是基于底层容器封装而成的容器适配器,提供了队列的操作,如入队(push)、出队(pop)和访问队首元素(front)。std::priority_queue:优先队列(Priority Queue)是一种特殊的队列,元素按照一定的优先级进行排序。std::priority_queue是基于底层容器封装而成的容器适配器,提供了优先队列的操作,如插入元素(push)、移除顶部元素(pop)和访问顶部元素(top)。
容器适配器的作用在于简化了特定数据结构的使用和操作。通过使用容器适配器,可以避免手动操作底层容器的复杂性,从而提高代码的可读性和可维护性。容器适配器隐藏了底层容器的细节,只暴露了特定数据结构的操作,使得开发者可以更专注于解决问题而不必关心底层容器的具体实现。
C++ STL学习之【容器适配器】-阿里云开发者社区 (aliyun.com)
五.Iterators and Pointers
1.iterator


(1)input operator与output operator
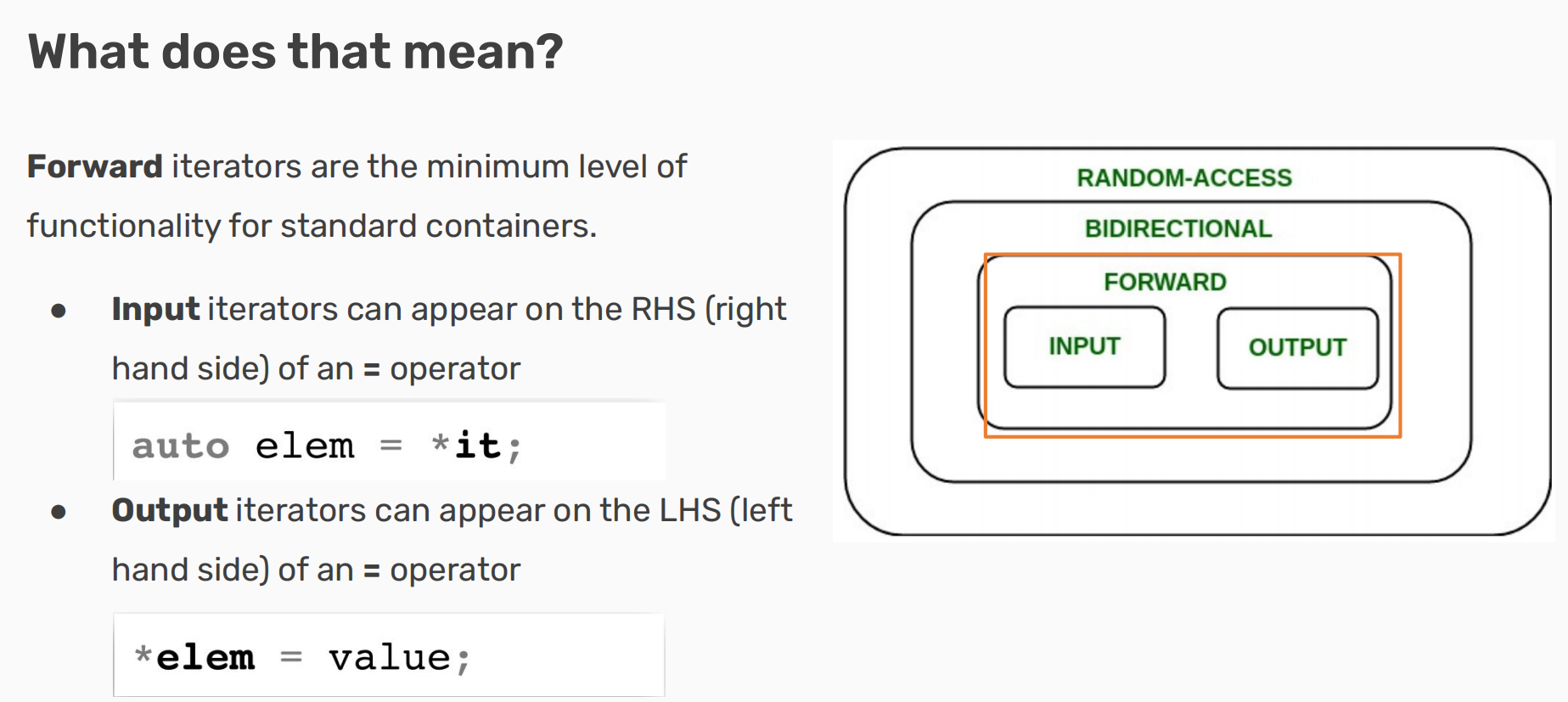
(2)Bidirectional iterator
Bidirectional iterators can go forward as well as backward!
● –iter;
● 具备forward iterators所有的功能
(3)Random-access iteraotr
直接访问元素,无需顺序遍历
● iter += 5;
● vectors; vec[1] or vec[17] or…
● 小心不要越界
(4)不是所有的STL容器都有迭代器

vector和deque都有很强的迭代器,可以随机访问。
2.Pointer
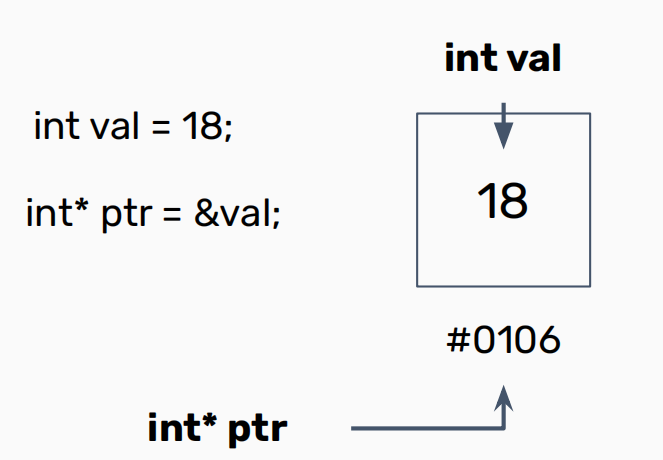
“*” ——> 解引用
-
迭代器和指针的区别
(1)迭代器是一种特殊的指针
(2)迭代器只能指向容器中的元素,指针可以指任何对象
(3)指针可以用&访问内存地址,用*访问某个地址处的数据值。
六.class
1.class和struct有什么区别
类包括了一系列的各种类型的属性,一系列成员函数去操纵这些属性,而且还为访问这些属性和函数设置了限制。
但是结构体没有这些限制,结构体可以视为没有访问限制的类。
2.头文件和源文件
头文件用来定义函数,源文件来实现函数,一个是接口,一个是逻辑细节。

3.构造器重载
#include "Student.h"
#include<string>
//默认构造器
Student::Student(){
name= "ysy";
state = "CA";
age = 18;
}
//参数构造器
Student::Student(std::string name,std::string state,int age){
this->name = name;
this->state = state;
this->age = age;
}
//析构函数
Student::~Student(){
delete [] my_array;
}
七.Template Classes

1.类模板
#include "Container.hh"
template<class T>
Container<T>::Container(T val){
this->value = val;
}
template <typename T>
T Container<T>::getValue(){
return value;
}
2.Const Correctness
std::string stringify(const Student& s){
return s.getName() + " is " + std::to_string(s.getAge()) + " years old." ;
}
保证了s不能被修改,但是编译器会报错,因为编译器不知道getName和getAge是否会修改s。
解决办法就是把getName和getAge都声明和定义为常量成员函数
#include “Student.h”
#include <string>
std::string Student::getName() const {
return this->name;
}
std::string Student::getState() {
return this->state;
}
int Student::getAge() const {
return this->age;
}
const_cast:
const_cast是一种C++运算符,主要是用来去除复合类型中const和volatile属性(没有真正去除)。
我们需要注意的是:变量本身的const属性是不能去除的,要想修改变量的值,一般是去除指针(或引用)的const属性,再进行间接修改。
- 用法:**const_cast
(expression)**
通过const_cast运算符,也只能将const type转换为type,将const type&转换为type&。
也就是说源类型和目标类型除了const属性不同,其他地方完全相同。
八.Template function
1.C++20新增的Constraints和Concepts

一文读懂C++20新特性之概念、约束(concept, constraint)_template constraint-CSDN博客
2.模板元编程
C++11模版元编程 - qicosmos(江南) - 博客园 (cnblogs.com)
C++元编程(C++ Metaprogramming)是一种在编译时进行计算和代码生成的技术。它利用C++的模板和编译期计算能力,允许在编译时生成代码、执行计算和进行类型转换等操作。C++元编程可以用于实现泛型算法、静态多态性、模板元编程库等。
C++元编程的实现主要依赖于以下两个特性:
- 模板:C++模板是一种在编译时生成代码的机制。通过在编译时对模板参数进行计算和替换,可以实现在编译时生成不同的代码。使用模板元编程技术,可以在模板参数中进行类型计算、条件分支、迭代和递归等操作,生成更灵活和高效的代码。
- 编译期计算:C++编译器在编译时可以执行一些简单的计算操作,例如常量表达式的求值、类型计算和类型转换等。通过利用这种编译期计算的能力,可以在编译时生成一些具有运行时特性的代码。
//用模板元编程实现阶乘计算
#include<iostream>
template<int N>
struct Factorial{
static const int value = N * Factorial<N-1>::value;
};
template<>
struct Factorial<0>{
static const int value = 1;
};
int main(){
const int result = Factorial<5>::value;
std::cout << "5的阶乘为:" << result << std::endl;
return 0;
}
3.constexpr
constexpr 是 C++11 引入的关键字,用于声明在编译时求值的常量表达式。它允许在编译时计算表达式的值,并将其用作编译时常量,从而提供了更高效和更灵活的编程方式。
使用 constexpr 关键字可以将函数、对象和变量声明为编译时常量,具有以下特点:
- 在编译时求值:
constexpr变量和函数在编译阶段进行求值,而不是在运行时。这意味着它们的值在程序执行之前就已经确定。 - 用于常量表达式:
constexpr变量和函数必须满足一定的条件,以使其能够在编译时求值。这些条件包括表达式是常量表达式、函数体只包含返回语句、函数参数和局部变量都是字面值类型等。
下面是一些使用 constexpr 的示例:
// 声明一个 constexpr 变量
constexpr int factorial(int n) {
return (n <= 1) ? 1 : n * factorial(n - 1);
}
int main() {
constexpr int result = factorial(5); // 在编译时计算 5 的阶乘
static_assert(result == 120, "Error: factorial(5) should be 120");
// 声明一个 constexpr 函数
constexpr int square(int x) {
return x * x;
}
constexpr int squared_result = square(result); // 在编译时计算 result 的平方
static_assert(squared_result == 14400, "Error: square(result) should be 14400");
return 0;
}
九. operators overloading
1.不能被重载的
:: ? . .* sizeof() typeid() cast()
2.非成员函数重载——friend
//student.h
[TITLE]
class Student {
public:
/* ... */
friend bool operator < (const Student& lhs, const Student& rhs)
const;
private:
/* ... */
bool operator < (const Student& lhs, const Student& rhs) {
return lhs.age < rhs.age;
}
十.special member functions
1.六大特殊成员函数
- 默认构造函数
- 构造函数
- 拷贝构造函数
- 拷贝赋值运算符
- 移动构造函数
- 移动赋值运算符

(1)默认构造函数
默认构造函数在创建对象时被调用,并用于初始化对象的成员变量。如果类没有显式定义构造函数,编译器会自动生成默认构造函数。如果类中定义了自定义构造函数(带参数的构造函数),则需要显式定义默认构造函数。默认构造函数可以执行一些初始化操作,例如将成员变量设置为默认值。
class Person {
public:
// 默认构造函数
Person() {
age = 0;
name = "Unknown";
}
private:
int age;
std::string name;
};
(2)拷贝构造函数
拷贝构造函数用于创建一个新对象,并将其初始化为与另一个同类型对象相同的值。拷贝构造函数通常用于在创建对象时,使用同类型的已存在对象进行初始化。当对象被传递给函数作为参数、通过值进行返回或者进行对象之间的赋值操作时,拷贝构造函数会被调用,默认情况下,拷贝构造函数会创建每个成员变量的副本。
class Person {
public:
// 默认构造函数
Person() {
age = 0;
name = "Unknown";
}
// 拷贝构造函数
Person(const Person& other) {
age = other.age;
name = other.name;
}
private:
int age;
std::string name;
};
(3)拷贝赋值运算符
拷贝赋值运算符用于将一个对象的值赋给另一个对象。拷贝赋值运算符通常用于对象之间的赋值操作,使一个对象的状态与另一个对象相同。
class MyClass {
public:
// 构造函数
MyClass(int value) : data(value) {}
// 拷贝赋值运算符
MyClass& operator=(const MyClass& other) {
// 检查自赋值
if (this == &other) {
return *this;
}
// 执行赋值操作
data = other.data;
return *this;
}
private:
int data;
};
在上述示例中,MyClass类定义了一个包含整数数据的成员变量data。拷贝赋值运算符将另一个MyClass对象的data值赋给当前对象的data成员变量
MyClass obj1(10);
MyClass obj2(20);
obj1 = obj2; // 使用拷贝赋值运算符将 obj2 的值赋给 obj1
深拷贝和浅拷贝区别:
- 浅拷贝(Shallow Copy): 浅拷贝是一种简单的复制策略,它只复制对象的成员变量的值,而不复制指向动态分配内存的指针。这意味着原始对象和复制后的对象将共享相同的内存资源。如果其中一个对象修改了共享的资源,会影响到其他对象。
class ShallowCopy {
public:
ShallowCopy(int size) {
data = new int[size];
}
// 浅拷贝构造函数
ShallowCopy(const ShallowCopy& other) {
data = other.data; // 只复制指针,共享相同的内存
}
private:
int* data;
};
//浅拷贝构造函数只是简单地复制了指向动态分配内存的指针,而没有创建新的内存副本。这样,原始对象和复制后的对象将共享相同的内存块。如果其中一个对象修改了data指向的内存,会影响到另一个对象
- 深拷贝(Deep Copy): 深拷贝是一种更复杂的复制策略,它不仅复制对象的成员变量的值,而且还复制指向动态分配内存的指针所指向的数据。这样,原始对象和复制后的对象将具有彼此独立的内存资源,修改一个对象的数据不会影响到另一个对象。
class DeepCopy {
public:
DeepCopy(int size) {
data = new int[size];
}
// 深拷贝构造函数
DeepCopy(const DeepCopy& other) {
data = new int[size];
for (int i = 0; i < size; ++i) {
data[i] = other.data[i]; // 复制每个元素的值
}
}
private:
int* data;
};
- 浅拷贝只是简单地复制对象的成员变量的值,包括指针,这意味着原始对象和复制后的对象共享相同的内存资源。
- 深拷贝创建一个新的内存块,并将原始对象的数据逐个复制到新的内存块中,使得原始对象和复制后的对象拥有彼此独立的内存资源。
在C++面向对象编程中,移动构造器(Move Constructor)和移动赋值运算符(Move Assignment Operator)是用于实现对象的移动语义和高效资源管理的特殊成员函数。它们是C++11引入的新特性,旨在提高对象的性能和效率。
(4)移动构造器: 移动构造器用于将一个已有对象的资源转移到另一个对象中,同时将原对象置于有效但未指定的状态。它采用右值引用(Rvalue Reference)作为参数,通常以&&表示。移动构造器的语法如下:
class MyClass {
public:
// 移动构造器
MyClass(MyClass&& other) {
// 将资源从other对象转移到当前对象
// 执行资源的移动操作,而非拷贝操作
}
};
移动构造器通过使用右值引用来接收一个临时对象或将要销毁的对象,并将其资源(如堆内存、文件句柄等)转移到当前对象中,避免了不必要的拷贝操作,提高了性能和效率。
(5)移动赋值运算符: 移动赋值运算符用于将一个已有对象的资源转移到另一个已存在的对象中,并释放原对象的资源。它也采用右值引用作为参数。移动赋值运算符的语法如下:
class MyClass {
public:
// 移动赋值运算符
MyClass& operator=(MyClass&& other) {
if (this != &other) {
// 释放当前对象的资源
// 将资源从other对象转移到当前对象
// 执行资源的移动操作,而非拷贝操作
}
return *this;
}
};
移动赋值运算符首先检查当前对象和目标对象是否是同一个对象,以防止自我赋值。然后释放当前对象的资源,并将资源从源对象转移到当前对象中。最后,返回当前对象的引用,以支持连续赋值操作。
使用移动构造器和移动赋值运算符可以在处理大型对象或包含大量资源的对象时减少不必要的拷贝操作,提高程序的性能和效率。
移动构造器和移动赋值运算符只在以下几个条件下生成:
- 没有拷贝操作被声明
- 没有移动操作被声明
- 没有析构函数被声明
十一.Move Semantics
1.std::move()
std::move() 是一个 C++ 标准库中的函数,位于 <utility> 头文件中。它允许将一个左值强制转换为右值引用,用于支持移动语义。通过使用 std::move(),可以避免不必要的数据复制,提高程序的性能。
std::move() 的使用方法:
std::move() 接受一个左值参数,并返回一个将其强制转换为右值引用的结果。这样做使得编译器能够知道该对象可以被移动而不是被复制。
#include <iostream>
#include <utility>
int main() {
std::string str1 = "Hello";
std::string str2 = std::move(str1); // 使用 std::move() 将 str1 转换为右值引用
std::cout << "str1 after move: " << str1 << std::endl; // str1 现在处于有效但未定义的状态
std::cout << "str2: " << str2 << std::endl;
return 0;
}
在上面的示例中,std::move(str1) 将 str1 转变为右值引用,从而允许将 str1 的资源所有权移交给 str2,而不是执行字符串的深层复制。在移动后,str1 的状态变为有效但未定义(valid but unspecified)。
- 注意事项:
- 使用
std::move()后,被移动的对象处于有效但未定义的状态,因此在移动后应谨慎操作。 - 使用
std::move()时,确保你不再需要原始对象中的值,因为移动后原始对象的状态可能是未定义的。
- 使用
举例:
//第一段
std::vector<char> initialData = {'A', 'T', 'G', 'C'};
HumanGenome genome(initialData);
/// pipelines are independent of each other
genome = stage1(genome);
genome = stage2(genome);
genome = stage3(genome);
//第二段
std::vector<char> initialData = {'A', 'T', 'G', 'C'};
HumanGenome genome(initialData);
/// pipelines are independent of each other
genome = stage1(std::move(genome));
genome = stage2(std::move(genome));
genome = stage3(std::move(genome));
区别
- 传递方式:
- 第一段代码:
genome是通过拷贝传递的。这意味着每次调用stage1、stage2和stage3时,都会创建genome对象的副本。 - 第二段代码:
genome是通过移动传递的(使用std::move)。这意味着每次调用stage1、stage2和stage3时,genome对象的资源(如内存)会被转移到新的HumanGenome对象中,而不是创建副本。
- 第一段代码:
- 性能:
- 第一段代码:由于每次传递都涉及到对象的拷贝,可能会有较高的性能开销,特别是当
HumanGenome对象包含大量数据时。 - 第二段代码:使用
std::move进行移动传递,可以避免不必要的对象拷贝,提高性能。移动语义通常比拷贝语义更高效,尤其是对于包含大量数据的对象。
- 第一段代码:由于每次传递都涉及到对象的拷贝,可能会有较高的性能开销,特别是当
- 资源管理:
- 第一段代码:每次函数调用都会创建和销毁临时的
HumanGenome对象,可能会增加内存管理的开销。 - 第二段代码:通过移动语义传递,资源管理更为高效,因为它减少了内存分配和释放的次数。
- 第一段代码:每次函数调用都会创建和销毁临时的
2.移动语义
如果类定义了复制构造函数和复制赋值,则还应定义移动构造函数和移动赋值。
十二.optional and Type Safety
如果有自我管理的成员变量,不需要定义自定义构造函数和运算符。
如果定义自定义析构函数,则还需要定义自定义复制构造函数和复制赋值运算符。
如果有自定义复制构造函数和复制赋值运算符,则还应该定义移动构造函数和移动赋值运算符。
1.std::optional
std::optional 是 C++17 标准中引入的一个模板类,用于封装可选值。它提供了一种方式来表示一个值可能存在,也可能不存在的情况,这在函数返回值、容器元素等方面非常有用。使用 std::optional 可以避免使用 std::nullopt 或 std::unique_ptr 等特殊值来表示“无值”状态。
以下是 std::optional 的一些关键特性和用法:
构造函数:
- 默认构造:创建一个不含值的
std::optional实例。std::optional<int> opt; // 默认构造,opt 没有值 - 有值构造:创建一个包含给定值的
std::optional实例。std::optional<int> opt(10); // 有值构造,opt 包含值 10 - 从
std::nullopt构造:std::nullopt是一个全局常量,用于表示std::optional没有值的状态。std::optional<int> opt(std::nullopt); // 从 std::nullopt 构造,opt 没有值
成员函数:
has_value():返回一个布尔值,指示std::optional是否包含值。if (opt.has_value()) { // opt 包含值 } else { // opt 不包含值 }value():返回存储的值。如果std::optional没有值,将抛出一个std::bad_optional_access异常。int value = opt.value(); // 如果 opt 包含值,则返回该值value_or(T&&):返回存储的值,如果std::optional没有值,则返回给定的默认值。int value = opt.value_or(42); // 如果 opt 包含值,则返回该值,否则返回 42emplace():在std::optional对象中直接构造一个新值,这可以避免拷贝或移动现有值。opt.emplace(20); // 如果 opt 没有值,将构造一个值为 20 的新值reset():将std::optional对象重置为不含值的状态。opt.reset(); // opt 现在没有值
比较运算符:
std::optional提供了==和!=运算符,用于比较两个std::optional对象。如果两个std::optional都包含值,它们将比较这些值;如果一个包含值而另一个不包含,它们不相等;如果两个都不包含值,它们相等。
特殊值:
std::nullopt:用于表示std::optional没有值的状态。
用途:
- 作为函数的返回类型,表示函数可能不返回有效的值。
- 作为类成员,表示某个属性可能是可选的。
- 在算法中,作为容器元素,表示某些元素可能是可选的。
std::optional 是 C++ 标准库中一个非常有用的工具,它提供了一种类型安全的方式来处理可能不存在的值,避免了使用 nullptr 或特殊值带来的潜在错误和复杂性。
十三.RAII and Smart Pointers
1.RALL
RAII(Resource Acquisition Is Initialization)是一种 C++ 编程中的重要设计模式,用于管理资源的获取和释放。在 RAII 中,资源的获取和释放是通过对象的生命周期来管理的,这种方式能够确保资源在合适的时候被正确释放,从而避免资源泄漏。
RAII 的原则和优点:
-
资源获取即初始化:资源的获取操作被放置在对象的构造函数中,确保在对象创建时资源被正确获取。
-
资源释放即析构:资源的释放操作被放置在对象的析构函数中,确保在对象生命周期结束时资源被正确释放。
-
异常安全性:RAII 可以确保即使在发生异常的情况下,资源也会被正确释放,避免资源泄漏。
-
简化资源管理:RAII 可以简化资源管理的代码,避免手动管理资源的复杂性。
示例代码演示 RAII:
下面是一个简单的示例,演示了如何使用 RAII 来管理文件资源:
#include <iostream>
#include <fstream>
#include <string>
class File {
public:
File(const std::string& filename) : file(filename) {
if (!file.is_open()) {
std::cerr << "Failed to open file: " << filename << std::endl;
}
}
~File() {
if (file.is_open()) {
file.close();
}
}
void write(const std::string& data) {
if (file.is_open()) {
file << data;
}
}
private:
std::ofstream file;
};
int main() {
File myFile("example.txt");
myFile.write("Hello, RAII!");
// 文件在作用域结束时会自动关闭
return 0;
}
在上面的示例中,File 类用于管理文件资源。当 File 对象 myFile 超出作用域时,其析构函数会自动调用,关闭文件资源。这样就确保了文件资源的正确释放,即使在发生异常的情况下也是如此。
通过 RAII,C++ 开发者可以更容易地管理资源,提高代码的可靠性和可维护性。
- std::lock_guard
std::lock_guard 是 C++ 标准库提供的一个用于管理互斥锁(std::mutex)的 RAII(资源获取即初始化)风格的封装类。RAII 是一种 C++ 编程中常用的资源管理技朮,它可以确保在作用域结束时自动释放资源,避免资源泄漏。
在多线程编程中,使用互斥锁是一种常见的方式来保护共享资源,以避免竞态条件。std::lock_guard 提供了一种便捷的方式来管理互斥锁的锁定和解锁,无需手动调用 lock() 和 unlock() 方法。
下面是一个简单的示例说明 std::lock_guard 的使用:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
void shared_print(const std::string& msg, int id) {
std::lock_guard<std::mutex> lock(mtx); // 在这里创建 lock_guard 对象,对互斥锁进行锁定
std::cout << "Thread " << id << ": " << msg << std::endl;
// 在此作用域结束时,lock_guard 对象将自动释放互斥锁
}
int main() {
std::thread t1(shared_print, "Hello from thread", 1);
std::thread t2(shared_print, "Bonjour from thread", 2);
t1.join();
t2.join();
return 0;
}
在上面的示例中,std::lock_guard<std::mutex> 的对象 lock 在 shared_print 函数中创建,它会在构造时锁定 mtx 互斥锁,在作用域结束时自动释放该互斥锁。这样可以确保在 std::cout 输出时只有一个线程能访问共享资源。
使用 std::lock_guard 可以简化代码,避免忘记在适当的位置解锁互斥锁,从而提高多线程编程的安全性和可靠性。
2.智能指针
C++ 智能指针是一种用于管理动态分配内存的指针类,它可以帮助避免常见的内存泄漏和悬挂指针等问题。在 C++11 标准之后,C++ 提供了三种主要的智能指针类型:std::unique_ptr、std::shared_ptr 和 std::weak_ptr。下面是对这些智能指针的详细介绍:
std::unique_ptr:std::unique_ptr允许只有一个指针可以指向动态分配的内存。这是一种独占所有权的智能指针。- 当
std::unique_ptr被销毁时,它将自动释放它持有的内存。 - 不能进行复制,但可以进行移动。
- 可以使用
std::move转移所有权。
#include <memory>
std::unique_ptr<int> ptr(new int(42));
std::shared_ptr:std::shared_ptr允许多个指针共享相同的动态分配内存。- 内部使用引用计数来跟踪共享指针的数量,当引用计数为零时,内存被释放。
- 允许复制和移动。
#include <memory>
std::shared_ptr<int> ptr1 = std::make_shared<int>(42);
std::shared_ptr<int> ptr2 = ptr1;
std::weak_ptr:std::weak_ptr是用于解决std::shared_ptr循环引用问题的一种方式。std::weak_ptr允许观察std::shared_ptr指向的对象,但不拥有对象的所有权。- 通过
std::weak_ptr的lock()方法可以获取一个指向对象的std::shared_ptr,但需要检查返回的std::shared_ptr是否为空。
#include <memory>
std::shared_ptr<int> shared_ptr = std::make_shared<int>(42);
std::weak_ptr<int> weak_ptr = shared_ptr;
if (auto ptr = weak_ptr.lock()) {
// 使用 ptr
}
智能指针可以大大简化内存管理,并有助于避免常见的内存泄漏和悬挂指针问题。但需要注意的是,虽然智能指针可以减少手动内存管理的复杂性,但仍然需要小心处理循环引用等特殊情况,以避免内存泄漏。
3.C++程序的构建
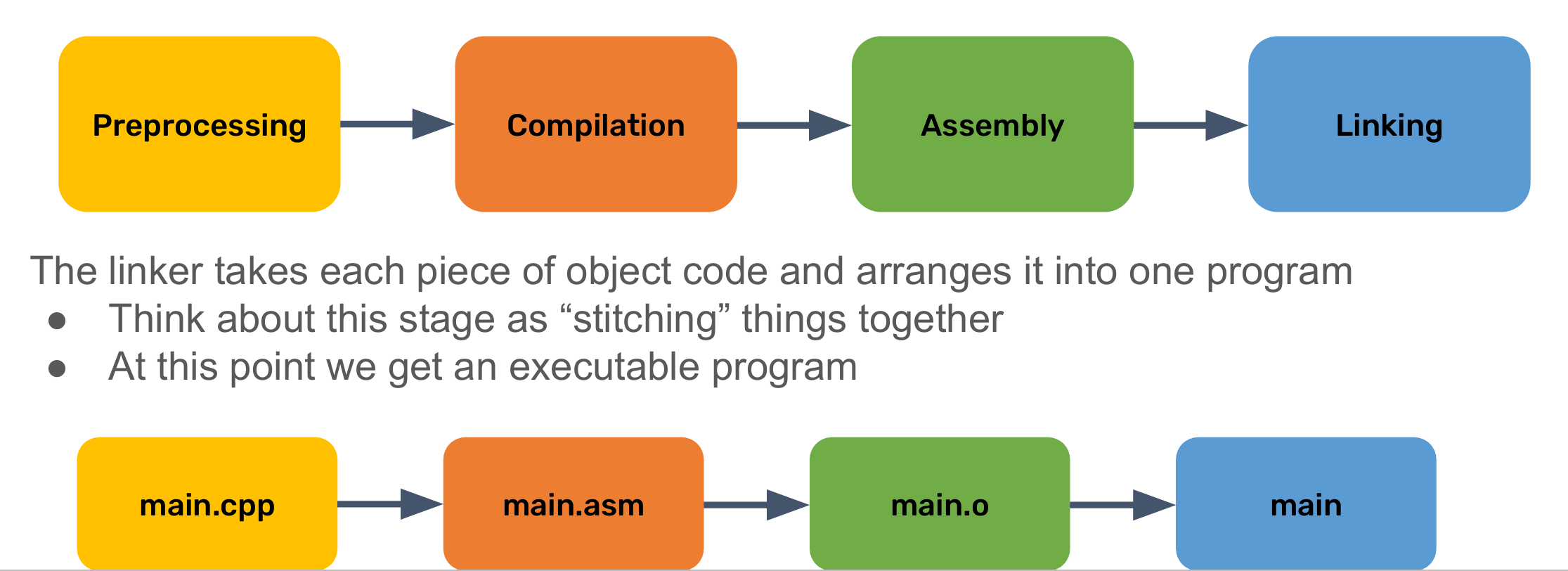
make和makefile:
Make 是一个用于构建程序的工具,通常用于自动化编译和链接过程。通过一个名为 Makefile 的文件,Make 工具可以根据文件的依赖关系和规则来确定哪些文件需要重新编译以生成最终的目标文件。Makefile 是一个包含规则和命令的文本文件,描述了文件之间的依赖关系以及如何生成最终的目标文件。
Makefile 是一个包含了一组规则的文本文件,用于告诉 Make 工具如何构建和更新程序。Makefile 包含了以下主要内容:
-
目标(Targets):目标是 Makefile 中定义的需要生成的文件、命令、或者动作。每个目标通常对应于一个最终的生成物。
-
依赖关系(Dependencies):依赖关系指定了一个目标文件所依赖的其他文件或目标。如果依赖的文件发生了变化,那么目标文件就需要重新生成。
-
规则(Rules):规则指定了如何生成目标文件以及生成目标文件所需的命令。每个规则包含一个目标、一个或多个依赖项,以及生成目标的命令。
-
命令(Commands):命令是 Makefile 中的操作步骤,用于生成目标文件。命令通常是 shell 命令,可以是编译、链接、复制文件等操作。
Makefile 的基本结构如下:
target: dependencies
command
target是需要生成的目标文件或动作。dependencies是target所依赖的文件或目标。command是生成target所需要执行的命令。
Make 工具会根据 Makefile 中定义的规则和依赖关系来决定哪些目标需要重新构建,以及如何构建它们。通过 Makefile,开发者可以轻松地管理和维护复杂的项目,实现自动化构建过程,提高开发效率。
使用 Make 工具和 Makefile 可以大大简化软件项目的构建过程,减少手动操作,提高代码的可维护性和可重复性。
cmake:
| [CMake 保姆级教程(上) | 爱编程的大丙 (subingwen.cn)](https://subingwen.cn/cmake/CMake-primer/index.html) |
十四.Assignment
assignment1、6、7不开放
assignment2 MarriagePact
Part1: Get all applicants
get_applicants :
#include <iostream>
#include <fstream>
#include<set>
#include<string>
int main()
{
std::set<std::string>S;
std::string line;
std::ifstream inputfile("C:\\tempstore\\assignment\\marriagepact_starter\\students.txt");
if(inputfile.is_open()){
while(std::getline(inputfile,line)){
S.insert(line);
std::cout<<line<<std::endl;
}
}
inputfile.close();
system("pause");
return 0;
}
回答问题:
#include <iostream>
#include <fstream>
#include<set>
#include<string>
int main()
{
std::set<std::string>S;
std::string line;
std::ofstream outputfile("C:\\tempstore\\assignment\\marriagepact_starter\\short_answer.txt");
if(outputfile.is_open()){
outputfile<<"1.二者需要的头文件不同。"<<'\n';
outputfile.close();
}
outputfile.open("C:\\tempstore\\assignment\\marriagepact_starter\\short_answer.txt",std::ios::app);
if(outputfile.is_open()){
outputfile<<"2.ordered_set 底层实现逻辑是红黑树,所以set中的元素是有序的;而unordered_set的底层是哈希表,所以内部元素是无序的。"<<'\n';
outputfile<<"3.floor(stu_name/strlen(stu_name))"<<'\n';
outputfile.close();
}
system("pause");
return 0;
}
Part2 :Find matches
#include <iostream>
#include <fstream>
#include<set>
#include<Queue>
#include<string>
#define random(x) (rand()%x)
int main()
{
std::set<std::string>S;
std::queue<std::string*>Q;
std::string line;
std::ifstream inputfile("C:\\tempstore\\assignment\\marriagepact_starter\\students.txt");
if(inputfile.is_open()){
while(std::getline(inputfile,line)){
S.insert(line);
}
}
for(auto i=S.begin();i!=S.end();++i){
if( (*i)[0] == 'Y'){
//存入指向该名字的指针
Q.push(const_cast<std::string*>(&(*i)));
}
}
if(Q.size()==0){
std::cout<<"NO STUDENT FOUND";
}
//随机生成一个不超过队列中元素个数的数字
int lucknum = random(Q.size());
for(int j=1;j<=lucknum;j++){
Q.pop();
}
std::cout<<*(Q.front());
inputfile.close();
system("pause");
return 0;
}
回答问题部分:
#include <iostream>
#include <fstream>
#include<set>
#include<string>
int main()
{
std::set<std::string>S;
std::string line;
std::ofstream outputfile("C:\\tempstore\\assignment\\marriagepact_starter\\short_answer.txt");
if(outputfile.is_open()){
outputfile<<"1.二者需要的头文件不同。"<<'\n';
outputfile.close();
}
outputfile.open("C:\\tempstore\\assignment\\marriagepact_starter\\short_answer.txt",std::ios::app);
if(outputfile.is_open()){
outputfile<<"2.ordered_set 底层实现逻辑是红黑树,所以set中的元素是有序的;而unordered_set的底层是哈希表,所以内部元素是无序的。"<<'\n';
outputfile<<"3.floor(stu_name/strlen(stu_name))"<<'\n';
outputfile<<"4.容器适配器实现了对底层容器的封装,使用时可以忽略底层容器的影响。"<<'\n';
outputfile<<"5.可能会发生访问越界"<<'\n';
outputfile.close();
}
system("pause");
return 0;
}
assignment3 Make a class
//class.h
// Blank header file
#include<iostream>
class Student{
public:
Student(const std::string& Name,const std::string& state, int age,const std::string& Num);
Student();
const std::string& getName()const;
const std::string& getState()const;
const std::string& getNum()const;
int getAge()const;
void setName(const std::string& Name);
void setState(const std::string& State);
void setNum(const std::string& Num);
void setAge(int Age);
private:
std::string Name;
std::string State;
std::string Num;
int Age;
};
//class.cpp
// Blank cpp file
#include "class.h"
#include<string>
#include<iostream>
Student::Student(){
Name = "Ysy";
State = "CA";
Age = 22;
Num = "12202104";
}
Student::Student(const std::string& Name, const std::string& State, int Age, const std::string& Num){
this->Name=Name;
this->State=State;
this->Age=Age;
this->Num=Num;
}
const std::string& Student::getName()const {
return this->Name;
}
const std::string& Student::getState()const {
return this->State;
}
int Student::getAge()const {
return this->Age;
}
const std::string& Student::getNum()const {
return this->Num;
}
void Student::setName(const std::string& Name){
this->Name = Name;
}
void Student::setAge(int Age){
this->Age = Age;
}
void Student::setState(const std::string& State){
this->State = State;
}
void Student::setNum(const std::string& Num){
this->Num = Num;
}
//main.cpp
#include "class.h"
#include<iostream>
/*
* Assigment 3: Make a class!
* Requirements:
* Must have a custom constructor ❌
* Must have a default constructor ❌
- i.e. constructor overloading
* Must have private members (functions and/or variables) ❌
* Must have public members (functions) ❌
* Must have at least one getter function ❌
* Must have at least one setter function ❌
*/
int main() {
// initialize class and run this file
Student Stu("Ysy","CA",22,"12202104");
std::cout<<"Name:"<<Stu.getName()<<std::endl;
std::cout<<"State:"<<Stu.getState()<<std::endl;
std::cout<<"Age:"<<Stu.getAge()<<std::endl;
std::cout<<"Num:"<<Stu.getNum()<<std::endl;
//用set方法
Stu.setName("Ysy");
Stu.setState("CA");
Stu.setAge(22);
Stu.setNum("12202104");
std::cout<<"Name:"<<Stu.getName()<<std::endl;
std::cout<<"State:"<<Stu.getState()<<std::endl;
std::cout<<"Age:"<<Stu.getAge()<<std::endl;
std::cout<<"Num:"<<Stu.getNum()<<std::endl;
return 0;
}
在命令行进行编译和链接

assignment4 Weather Forecast
/*
Assignment 4: Weather Forecast
This assignment works with template functions and lambdas to become the best weather forecaster
at the Stanford Daily. Be sure to read the assignment details in the PDF.
Submit to Paperless by 11:59pm on 5/10/2024.
*/
// TODO: import anything from the STL that might be useful!
#include <iostream>
#include <vector>
#include<algorithm>
#include <fstream>
#include <numeric>
// TODO: write convert_f_to_c function here. Remember it must be a template function that always returns
// a double.
// [function definition here]
std::vector<double>result;
template<typename T>
double convert_f_to_c(T Fahrenheit){
return (Fahrenheit-32)*5/9;
}
bool func(double a,double b){
return a>b;
}
template<typename Function>
std::vector<double> get_forecast(std::vector<std::vector<double>> readings, Function fn) {
// TODO: write get_forecast here!
for(auto it = readings.begin();it!=readings.end();++it){
result.push_back(fn((*it)));
}
return result;
}
int main() {
std::vector<std::vector<double>> readings = {
{70, 75, 80, 85, 90},
{60, 65, 70, 75, 80},
{50, 55, 60, 65, 70},
{40, 45, 50, 55, 60},
{30, 35, 40, 45, 50},
{50, 55, 61, 65, 70},
{40, 45, 50, 55, 60}
};
std::ofstream outputfile("C:\\tempstore\\assignment\\weatherforecast_starter\\output.txt");
// TODO: Convert temperatures to Celsius and output to output.txt
if(outputfile.is_open()){
for(auto it = readings.begin();it!=readings.end();++it){
for(auto &elem : *it){
outputfile<<convert_f_to_c(elem)<<" ";
}
}
outputfile<< '\n';
outputfile.close();
}
// TODO: Find the maximum temperature for each day and output to output.txt
outputfile.open("C:\\tempstore\\assignment\\weatherforecast_starter\\output.txt",std::ios::app);
auto max_elem = [] (std::vector<double>& Day) -> double
{
return *max_element(Day.begin(),Day.end());
};
auto Max = get_forecast(readings,max_elem);
if(outputfile.is_open()){
for(auto &elem : Max){
outputfile<<elem<<" ";
}
}
outputfile<< '\n';
outputfile.close();
// TODO: Find the minimum temperature for each day and output to output.txt
outputfile.open("C:\\tempstore\\assignment\\weatherforecast_starter\\output.txt",std::ios::app);
auto min_elem = [] (std::vector<double>& Day) -> double
{
return *min_element(Day.begin(),Day.end());
};
auto Min = get_forecast(readings,min_elem);
if(outputfile.is_open()){
for(auto &elem : Min){
outputfile<<elem<<" ";
}
}
outputfile<< '\n';
outputfile.close();
// TODO: Find the average temperature for each day and output to output.txt
outputfile.open("C:\\tempstore\\assignment\\weatherforecast_starter\\output.txt",std::ios::app);
auto ave_elem = [] (std::vector<double>& Day) -> double
{
double sum = std::accumulate(Day.begin(), Day.end(), 0.0);
return sum / Day.size();
};
auto Ave = get_forecast(readings,ave_elem);
if(outputfile.is_open()){
for(auto &elem : Ave){
outputfile<<elem<<" ";
}
}
outputfile<< '\n';
outputfile.close();
return 0;
}
assignment5 Treebook
//user.h
#include <set>
#include <string>
class User {
public:
// TODO: write special member functions, including default constructor!
//default constructor
User();
User(std::string name);
//copy constructor
User(const User& U);
//Move constructor
User(User&& Us);
//Move assignment operator
User & operator = (User&& Us);
// getter functions
std::string getName() const;
std::set<User>& getFriends();
const std::set<User>& getFriends() const;
// setter functions
void setName(std::string name);
// TODO: add the < operator overload here!
bool operator <(const User& Ur)const;
private:
std::string name;
std::set<User> friends;
};
//user.cpp
#include "user.h"
#include <set>
#include <iostream>
#include <string>
User::User(std::string name) {
// TODO: Implement the additional constructor here!
this->name = name;
this->friends = std::set<User>{};
}
User::User(const User& U){
this->name=U.name;
this->friends = U.friends;
}
User::User(User&& Us){
this->name = Us.name;
this->friends = std::move(Us.friends);
}
User User::operator = (User&& Us){
this->name = Us.name;
this->friends = std::move(Us.friends);
return *this;
}
std::string User::getName() const {
return name;
}
std::set<User>& User::getFriends() {
return friends;
}
// A const version is needed to allow read-only access to the friends set!
const std::set<User>& User::getFriends() const {
return friends;
}
void User::setName(std::string name) {
this->name = name;
}
// TODO: Implement the < operator overload here!
bool operator <(const User& Ur)const{
return this->getName() < Ur.getName();
}
//main.cpp
#include <iostream>
#include "User.h"
// TODO: Implement the non-member function + operator overload here!
void operator +(User& name1,User& name2){
//相互添加
name1.getFriends.insert(name2);
name2.getFriends.insert(name1);
}
void printFriends(const User& user) {
std::cout << user.getName() << " is friends with: " << std::endl;
for(auto& user : user.getFriends()) {
std::cout << " " << user.getName() << std::endl;
}
}
int main() {
// create a bunch of users
User alice("Alice");
User bob("Bob");
User charlie("Charlie");
User dave("Dave");
// make them friends
alice + bob;
alice + charlie;
dave + bob;
charlie + dave;
// print out their friends
printFriends(alice);
printFriends(bob);
printFriends(charlie);
printFriends(dave);
return 0;
}